THREDDS Client Catalog Primer
A THREDDS Catalog describes what datasets a server has, and how they can be accessed.
A catalog is an XML document that follows the THREDDS Catalog
schema.
This section will describe the client view of the catalog. If you are maintaining a TDS
server, you will also need to add other information to the catalog,
which is used only by the server and is not seen by the client.
THREDDS catalogs collect, organize, and describe accessible datasets. They provide a hierarchical structure for
organizing the datasets as well as an access method (URL) and a human-understandable name for each dataset.
Further descriptive information about each dataset can also be added.
Here's an example of a very simple catalog:
1 <?xml version="1.0" ?>
2 <catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0" >
3 <service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
4 <dataset name="SAGE III Ozone 2006-10-31" serviceName="odap" urlPath="sage/20061031.nc" ID="20061031.nc"/>
5 </catalog>
with this line-by-line explanation:
- The first line indicates that this is an XML document.
- This is the root element of the XML, the
catalog element. It must declare the thredds
catalog namespace with the xmlns attribute exactly as shown.
- This declares a service named
odap that will serve data via the OpenDAP protocol.
Many other data access services come bundled with THREDDS.
- This declares a dataset named
SAGE III Ozone 2006-10-31. It references the
odap service, meaning that it will be served via OpenDAP. The URL to access the dataset is discussed next.
- This closes the
catalog element.
Using the catalog directly above, here are the steps for client software to construct a dataset access URL:
- Find the service referenced by the dataset:
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<dataset name="SAGE III Ozone 2006-10-31" serviceName="odap" urlPath="sage/20061031.nc" ID="20061031.nc"/>
- Append the service base path to the server root to construct the service base URL:
serverRoot = http://hostname:port
serviceBasePath = /thredds/dodsC/
serviceBaseUrl = serverRoot + serviceBasePath = http://hostname:port/thredds/dodsC/
- Find the URL path referenced by the dataset:
<dataset name="SAGE III Ozone 2006-10-31" serviceName="odap" urlPath="sage/20061031.nc" ID="20061031.nc"/>
- Append the dataset URL path to the service base URL to get the
dataset access URL:
serviceBaseUrl = http://hostname:port/thredds/dodsC/
datasetUrlPath = sage/20061031.nc
datasetAccessUrl = serviceBaseUrl + datasetUrlPath = http://hostname:port/thredds/dodsC/sage/20061031.nc
In summary, construct a URL from a client catalog with these 3 pieces:
http://hostname:port/thredds/dodsC/sage/20061031.nc
<------------------><------------><--------------->
server service dataset
When you have many datasets to declare in each catalog, you can use
nested datasets:
<?xml version="1.0" ?>
<catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0" >
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
1 <dataset name="SAGE III Ozone Loss Experiment" ID="Sage III">
2 <dataset name="January Averages" serviceName="odap" urlPath="sage/avg/jan.nc" ID="jan.nc"/>
2 <dataset name="February Averages" serviceName="odap" urlPath="sage/avg/feb.nc" ID="feb.nc"/>
2 <dataset name="March Averages" serviceName="odap" urlPath="sage/avg/mar.nc" ID="mar.nc"/>
3 </dataset>
</catalog>
- This declares a collection dataset which
acts as a container for the other datasets. Note that it ends in a
> instead
of />, and does not have a urlPath attribute.
- These are the datasets that directly point to data, called direct
datasets.
- This closes the collection dataset element on line 1.
You can add any level of nesting you want, e.g.:
<?xml version="1.0" ?>
<catalog name="Example" xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0" >
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<dataset name="SAGE III Ozone Loss Experiment" ID="Sage III">
<dataset name="Monthly Averages">
<dataset name="January Averages" serviceName="odap" urlPath="sage/avg/jan.nc" ID="jan.nc"/>
<dataset name="February Averages" serviceName="odap" urlPath="sage/avg/feb.nc" ID="feb.nc"/>
<dataset name="March Averages" serviceName="odap" urlPath="sage/avg/mar.nc" ID="mar.nc"/>
</dataset>
<dataset name="Daily Flight Data" ID="Daily Flight">
<dataset name="January">
<dataset name="Jan 1, 2001" serviceName="odap" urlPath="sage/daily/20010101.nc" ID="20010101.nc"/>
<dataset name="Jan 2, 2001" serviceName="odap" urlPath="sage/daily/20010102.nc" ID="20010102.nc"/>
</dataset>
</dataset>
</dataset>
</catalog>
Reference documentation
A complete listing of available properties can be found in the
catalog specification.
So far, we've used the name, serviceName, and urlPath attributes
to tell THREDDS how to treat our datasets. However, there are a lot of optional properties that can be added to
help other applications and digital libraries know how to "do the right thing" with our data.
Here is a sample of them:
- The
collectionType attribute is used on collection datasets to describe the relationship of
their nested datasets.
- The
dataType is a simple classification that helps clients to know how to display the data
(e.g. Image, Grid, Point data, etc).
- The
dataFormatType describes what format the data is stored in
(e.g. NetCDF, GRIB-2, NcML, etc).
This information is used by data access protocols like OpenDAP and HTTP.
- The combination of the naming
authority and the ID attributes should form a
globally-unique identifier for a dataset. In the TDS, it is especially important to add the ID
attribute to your datasets.
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/"/>
<dataset name="SAGE III Ozone Loss Experiment" ID="Sage III" collectionType="TimeSeries">
<dataset name="January Averages" serviceName="odap" urlPath="sage/avg/jan.nc"
ID="jan.nc" authority="unidata.ucar.edu">
<dataType>Trajectory</dataType>
<dataFormatType>NetCDF</dataFormatType>
</dataset>
</dataset>
Reference documentation
A complete listing of necessary attributes can be found
here.
Exporting THREDDS datasets to digital libraries
The harvest attribute indicates that the dataset is at the
right level of granularity to be exported to digital libraries or other discovery services.
Elements such as summary, rights, and publisher
are needed in order to create valid entries for these services.
<dataset name="SAGE III Ozone Loss Experiment" ID="Sage III" harvest="true">
<contributor role="data manager">John Smith</contributor>
<keyword>Atmospheric Chemistry</keyword>
<publisher>
<long_name vocabulary="DIF">Community Data Portal, National Center for Atmospheric Research, University Corporation for Atmospheric Research</long_name>
<contact url="http://dataportal.ucar.edu" email="cdp@ucar.edu"/>
</publisher>
</dataset>
When a catalog includes multiple datasets, it can often be the case that they have share
properties. For example:
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/"/>
<dataset name="SAGE III Ozone Loss Experiment" ID="Sage III">
<dataset name="January Averages" urlPath="sage/avg/jan.nc" ID="jan.nc" serviceName="odap" authority="unidata.ucar.edu" dataFormatType="NetCDF"/>
<dataset name="February Averages" urlPath="sage/avg/feb.nc" ID="feb.nc" serviceName="odap" authority="unidata.ucar.edu" dataFormatType="NetCDF"/>
<dataset name="March Averages" urlPath="sage/avg/mar.nc" ID="mar.nc" serviceName="odap" authority="unidata.ucar.edu" dataFormatType="NetCDF"/>
</dataset>
Rather than declare the same information on each dataset, you can use the metadata
element to factor out common information:
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/"/>
<dataset name="SAGE III Ozone Loss Experiment" ID="Sage III">
1 <metadata inherited="true">
2 <serviceName>odap</serviceName>
2 <authority>unidata.ucar.edu</authority>
2 <dataFormatType>NetCDF</dataFormatType>
</metadata>
3 <dataset name="January Averages" urlPath="sage/avg/jan.nc" ID="jan.nc"/>
3 <dataset name="February Averages" urlPath="sage/avg/feb.nc" ID="feb.nc"/>
4 <dataset name="Global Averages" urlPath="sage/global.nc" ID="global.nc" authority="fluffycats.com"/>
</dataset>
- The
metadata element with inherited="true" implies that all
the information inside the metadata element applies to the current dataset
and all nested datasets.
- The
serviceName, authority, and dataFormatType
are declared as elements.
- These datasets use all the metadata values declared in the parent dataset.
- This dataset overrides
authority, but uses the other 2 metadata values
When should I use a metadata element?
Both the dataset and metadata elements are containers for metadata called the threddsMetadata group. When the metadata is specific to the dataset, put it directly in the dataset element. When you want to share it with all nested datasets, put it in a metadata inherited="true" element.
It is very useful to break up large catalogs into pieces and separately
maintain each piece. One way to do this is to build each piece as a separate
and logically-complete catalog, then create a master catalog using catalog references:
<?xml version="1.0" encoding="UTF-8"?>
<catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0" name="Top Catalog"
1 xmlns:xlink="http://www.w3.org/1999/xlink">
2 <dataset name="Realtime data from IDD" ID="IDD">
3 <catalogRef xlink:href="idd/models.xml" xlink:title="NCEP Model Data" name="" />
3 <catalogRef xlink:href="idd/radars.xml" xlink:title="NEXRAD Radar" name="" />
3 <catalogRef xlink:href="idd/obsData.xml" xlink:title="Station Data" name="" />
3 <catalogRef xlink:href="idd/satellite.xml" xlink:title="Satellite Data" name="" />
</dataset>
4 <catalogRef xlink:title="Far Away University catalog" xlink:href="http://www.farAway.edu/thredds/catalog.xml" /> <!-- 4 -->
</catalog>
- We declare the xlink namespace in the catalog element.
- The collection (or container) dataset logically contains the
catalogRefs,
which are thought of as nested datasets whose contents are the contents of the external catalog.
- Here are several
catalogRef elements, each with a link to an external catalog,
using the xlink:href attribute.
The xlink:title is used as the name of the dataset. We need a name attribute
(in order to validate, for obscure reasons), but it is
ignored. The xlink:href attributes are relative URLS and are resolved against the catalog
URL. For example, if the catalog URL is:
http://thredds.ucar.edu/thredds/data/catalog.xml
then the resolved URL of the first catalogRef will be:
http://thredds.ucar.edu/thredds/data/idd/models.xml
catalogRefs needn't point to local catalogs only; this one points to a remote one at
Far Away University. - The metadata elements with inherited="true" are NOT not copied across catalogRefs. The catalog that a catalogRef refers to is stand-alone in that sense.
Reference documentation
A complete listing of recognized service types can be found in the
catalog specification.
Datasets can be made available through more than one access
method by defining and then referencing a compound service element. The following:
<service name="all" serviceType="Compound" base="" >
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<service name="wcs" serviceType="WCS" base="/thredds/wcs/" />
</service>
defines a compound service named all which contains two
nested services. Any dataset that reference the compound service will
have two access methods. For instance:
<dataset name="SAGE III Ozone 2006-10-31" urlPath="sage/20061031.nc" ID="20061031.nc">
<serviceName>all</serviceName>
</dataset>
would result in these two access URLs, one for OpenDAP access and one for WCS access:
/thredds/dodsC/sage/20061031.nc
/thredds/wcs/sage/20061031.nc
Note: the contained services can still be referenced independently. For instance:
<dataset name="Global Averages" urlPath="sage/global.nc" ID="global.nc">
<serviceName>odap</serviceName>
</dataset>
results in a single access URL:
/thredds/dodsC/sage/global.nc
As catalogs get more complicated, you should check that you haven't made any
errors. There are three components to checking:
- Is the XML well-formed?
- Is it valid against the catalog schema?
- Does it have everything it needs to be read by a THREDDS client?
You can check well-formedness using online tools like this one.
If you also want to check validity in those tools, you will need to declare the catalog
schema location like so:
<catalog name="Validation" xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0
https://schemas.unidata.ucar.edu/thredds/InvCatalog.1.0.6.xsd">
...
</catalog>
Reference documentation
The schema referenced in the example can be found
here.
However, you'll probably want to study the
catalog specification
instead, as it is much more digestable.
- The first bolded line declares the schema-instance namespace. Just copy it exactly as you see it here.
- The next two bolded lines tell your XML validation tool where to find the THREDDS XML schema document.
Just copy them exactly as you see them here.
Or, you can simply use the
THREDDS Catalog Validation service
to check all three components at once. This service already knows where the schemas are located, so it's not
necessary to add that information to the catalog; you only need it if you want to do your own validation.
The NetCDF Tools User Interface (aka ToolsUI) can read and display THREDDS catalogs. You can start it from the
command line, or
launch it
from webstart. Use the THREDDS Tab, and click on the
 button to navigate to a local catalog file, or enter in
the URL of a remote catalog, as below
(note that this is an XML document, not an HTML page!). The catalog will be displayed in a tree widget
on the left, and the selected dataset will be shown on the right, for example:
button to navigate to a local catalog file, or enter in
the URL of a remote catalog, as below
(note that this is an XML document, not an HTML page!). The catalog will be displayed in a tree widget
on the left, and the selected dataset will be shown on the right, for example:
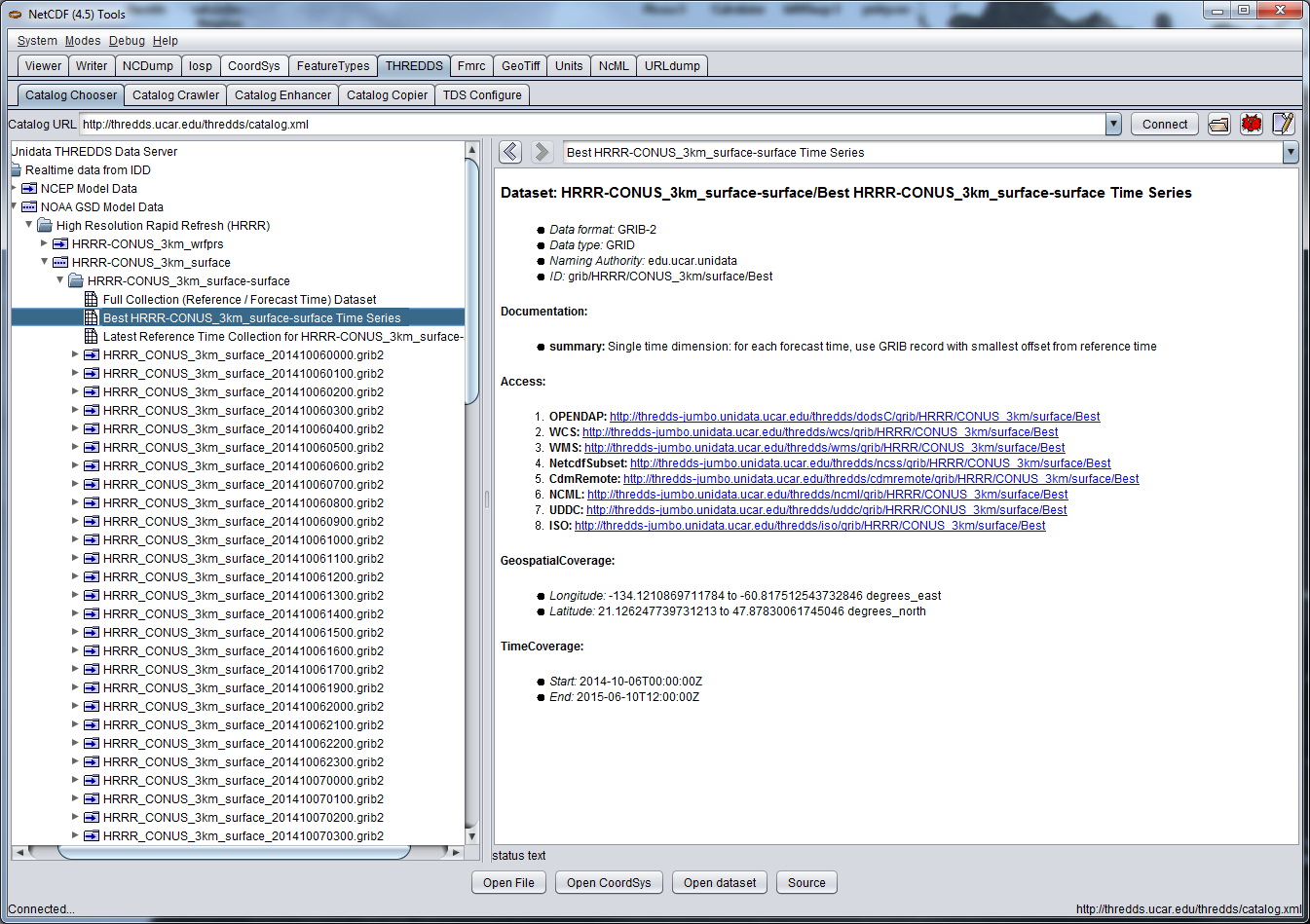
Once you get your catalog working in a TDS, you can enter the TDS URL directly, and view the datasets with the
Open buttons.