Unidata’s Common Data Model (CDM) is an abstract data model for scientific datasets. It merges the netCDF, OPeNDAP, and HDF5 data models to create a common API for many types of scientific data. The NetCDF Java library is an implementation of the CDM which can read many file formats besides netCDF. We call these CDM files, a shorthand for files that can be read by the NetCDF Java library and accessed through the CDM data model.
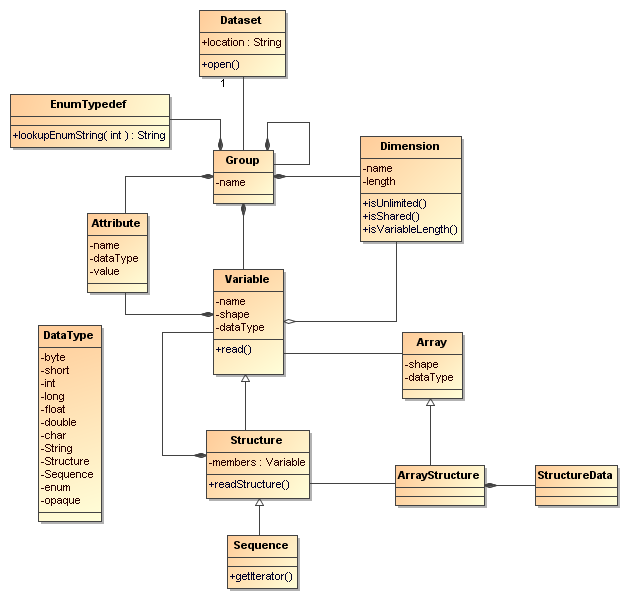
The Common Data Model has three layers, which build on top of each other to add successively richer semantics:
A Dataset may be a netCDF, HDF5, GRIB, etc. file, an OPeNDAP dataset, a collection of files, or anything else which can be accessed through the netCDF API. We sometimes use the term CDM dataset to mean any of these possibilities, and to emphasize that a dataset does not have to be a file in netCDF format.
A Group is a container for Attributes, Dimensions, EnumTypedefs, Variables, and nested Groups. The Groups in a Dataset form a hierarchical tree, like directories on a disk.There is always at least one Group in a Dataset, the root Group, whose name is the empty string.
A Variable is a container for data. It has a DataType, a set of Dimensions that define its array shape, and optionally a set of Attributes. Any shared Dimension it uses must be in the same Group or a parent Group.
A Dimension is used to define the array shape of a Variable. It may be shared among Variables, which provides a simple yet powerful way of associating Variables. When a Dimension is shared, it has a unique name within the Group. If unlimited, a Dimension's length may increase. If variableLength, then the actual length is data dependent, and can only be found by reading the data. A variableLength Dimension cannot be shared or unlimited.
An Attribute has a name and a value, and associates arbitrary metadata with a Variable or a Group. The value is a scalar or one dimensional array of Strings or numeric values, so the possible data types are (String, byte, short, int, long, float, double). The integer types (byte, short, int, long) may be signed or unsigned.
A Structure is a type of Variable that contains other Variables, analogous to a struct in C, or a row in a relational database. In general, the data in a Structure are physically stored close together on disk, so that it is efficient to retrieve all of the data in a Structure at the same time. A Variable contained in a Structure is a member Variable, and can only be read in the context of its containing Structure.
A Sequence is a one dimensional Structure whose length is not known until you actually read the data. To access the data in a Sequence, you can only iterate through the Sequence, getting the data from one Structure instance at a time.
An EnumTypedef is an enumeration of Strings, used by Variables of type enum.
An Array contains the actual data for a Variable after it is read from the disk or network. You get an Array from a Variable by calling read() or its variants. An Array is rectangular in shape (like Fortran arrays). There is a specialized Array type for each of the DataTypes.
An ArrayStructure is a subclass of Array that holds the data for Structure Variables. Essentially it is an array of StructureData objects.
DataType describes the possible types of data:
The primitive numeric types are byte, short, int, long, float and double. The integer types (8-bit byte, 16-bit short, 32-bit int, 64-bit long) may be signed or unsigned. Variable and Array objects have isUnsigned() methods to indicate, and conversion to wider types is correctly done.
A String is a variable length array of Unicode characters. A string is stored in a netCDF file as UTF-8 encoded Unicode (note that ASCII is a subset of UTF-8). Libraries may use different internal representations, for example the Java library uses UTF-16 encoding.
A char is an 8-bit byte that contains uninterpreted character data. Typically a char contains a 7-bit ASCII character, but the character encoding is application-specific. Because of this, one should avoid using the char type for data. A legitimate use of char is with netCDF classic files, to store string data or attributes. The CDM will interpret these as UTF-8 encoded Unicode, but 7-bit ASCII encoding is probably the only portable encoding.
An enum type is a list of distinct (integer, String) pairs. A Variable with enum type stores integer values, which can be converted to the String enum value. There are 3 enum types: enum1, enum2, and enum4, corresponding to storing the integer as a byte, short, or int.
An opaque type stores uninterpreted blobs of bytes. The length of the blob is not known until it is read. An array of opaque objects may have different lengths for each of the blobs.
An Object name refers to the name of a Group, Dimension, Variable, Attribute, or EnumTypedef. An object name is a String, a variable length array of Unicode characters. The set of allowed characters is still being considered.
The CDM data model is close to, but not identical with the netCDF-4 data model (informal UML). However there is a complete 2-way mapping between the two models. In the CDM:
See here for detailed mapping between the NetCDF-4 and CDM data models.
See here for more details on OPeNDAP processing.
As of version 4.1, the CDM can read all versions of HDF5 through version 1.8.4, except for the following HDF5 features:
Please send file examples if you find a problem with the CDM reading HDF5 files, other than the ones listed above.
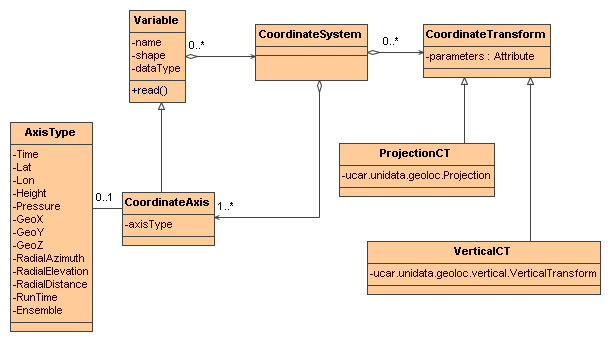
A Variable can have zero or more Coordinate Systems containing one or more CoordinateAxis. A CoordinateAxis can only be part of a Variable's CoordinateSystem if the CoordinateAxis' set of Dimensions is a subset of the Variable's set of Dimensions. This ensures that every data point in the Variable has a corresponding coordinate value for each of the CoordinateAxis in the CoordinateSystem.
A Coordinate System has one or more CoordinateAxis, and zero or more CoordinateTransforms.
A CoordinateAxis is a subtype of Variable, and is optionally classified according to the types in AxisType.
A CoordinateTransform abstractly represents a transformation between CoordinateSystems, and currently is either a Projection or a Vertical Transform.
The AxisType enumerations are specific to the case of georeferencing coordinate systems. Time refers to the real date/time of the dataset. Latitude and Longitude identify standard horizontal coordinates. Height and Pressure identify the vertical coordinate. GeoX and GeoY are used in transfomations (eg projections) to Latitude, Longitude. GeoZ is used in vertical transformations to vertical Height or Pressure. RadialAzimuth, RadialElevation and RadialDistance designate polar coordinates and are used for Radial DataTypes. RunTime and Ensemble are used in forecast model output data. Often much more detailed information is required (geoid reference, projection parameters, etc), so these enumerations are quite minimal.
These are the rules which restrict which Variables can be used as Coordinate Axes:
Structure { float lat; float lon; float data; data:coordinates = "lat lon"; } sample(*)Structure { float lat; float lon; Structure { float altitude; float data; data:coordinates = "lat lon altitude"; } profile(*) } station(*)
Formally, a Variable is thought of as a sampled function whose domain is an index range; each CoordinateAxis is a scalar valued function on the same range; each CoordinateSystem is therefore a vector-valued function on the same range consisting of its CoordinateAxis functions. To take it one step further, when the CoordinateSystem function is invertible, the Variable can be thought of as a sampled function whose domain is the range of the Coordinate System, that is on Rn (the product space of real numbers). To be invertible, each CoordinateAxis should be invertible. For a 1-dimensional CoordinateAxis this simply means the coordinate values are strictly monotonic. For a 2 dimensional CoordinateAxis, it means that the lines connecting adjacent coordinates do not cross each other. For > 2 dimensional CoordinateAxis, it means that the surfaces connecting the adjacent coordinates do not intersect each other.
Neither NetCDF, HDF5, or OPeNDAP have Coordinate Systems as part of their APIs and data models, so their specification in a file is left to to higher level libraries (like HDF-EOS) and to conventions. If you are writing netCDF files, we strongly recommend using CF Conventions.
NetCDF has long had the convention of specifying a 1-dimensional CoordinateAxis with a coordinate variable, which is a Variable with the same name as its single dimension. This is a natural and elegant way to specify a 1-dimensional CoordinateAxis, since there is an automatic association of the Coordinate Variable with any Varaible that uses its dimension. Unfortunately there are not similarly elegant ways to specify a multidimensional CoordinateAxis, and so various attribute conventions have sprung up, that typically list the CoordinateAxis variables, for example the CF Conventions has:
float lat(y,x);
float lon(y,x);
float temperature(y,x);
temperature:coordinates="lat lon";
Note that in this example, there is no CoordinateSystem object, so the same list has to be added to each Variable, and any CoordinateTransform specifications also have to be added to each Variable. However, the common case is that all the Variables in a dataset use the same Coordinate System.
The ucar.nc2.dataset layer reads various Conventions and extracts the Coordinate Systems using the CoordSysBuilder framework. We often use a set of internal attributes called the underscore Coordinate attributes as a way to standardize the Coordinate Systems infomation. Although these may work when working with Unidata software, we do not recommend them as a substitute for conventions such as CF.
Scientific Feature Types are a way to categorize scientific data. The CDM Feature Type layer turns CDM datasets into collections of Feature Type objects, and
allows a user to extract subsets of the Feature Types "in coordinate space" i.e. using spatial and temporal bounding boxes. In contrast, the CDM Data Access
layer provides array index space subsetting, and the client application must know how to map array indices into coordinate values.
With these Feature Types objects, mapping into other data models like ISO/OGC becomes possible.
Feature Type definitions, APIU, and encodings are still being developed, so applications using these must be able to evolve along with the APIs.
 This document is maintained by Unidata. Send comments to THREDDS support. Last updated: Oct 2014
This document is maintained by Unidata. Send comments to THREDDS support. Last updated: Oct 2014