for version 4.4+ of the Netcdf-Java/CDM library
An NcML document is an XML document (aka an instance document) whose contents are described and constrained by NcML Schema-2.2. NcML Schema-2.2 combines the earlier NcML core schema which is an XML description of the netCDF-Java / CDM data model, with the earlier NcML dataset schema, which allows you to define, redefine, aggregate, and subset existing netCDF files.
An NcML document represents a generic netCDF dataset, i.e. a container for data conforming to the netCDF data model. For instance, it might represent an existing netCDF file, a netCDF file not yet written, a GRIB file read through the netCDF-Java library, a subset of a netCDF file, an aggregation of netCDF files, or a self-contained dataset (i.e. all the data is included in the NcML document and there is no separate netCDF file holding the data). An NcML document therefore should not necessarily be thought of as a physical netCDF file, but rather the “public interface” to a set of data conforming to the netCDF data model.
NcML Schema-2.2 is written in the W3C XML Schema language, and essentially represents the netCDF-Java / CDM data model, which schematically looks like this in UML
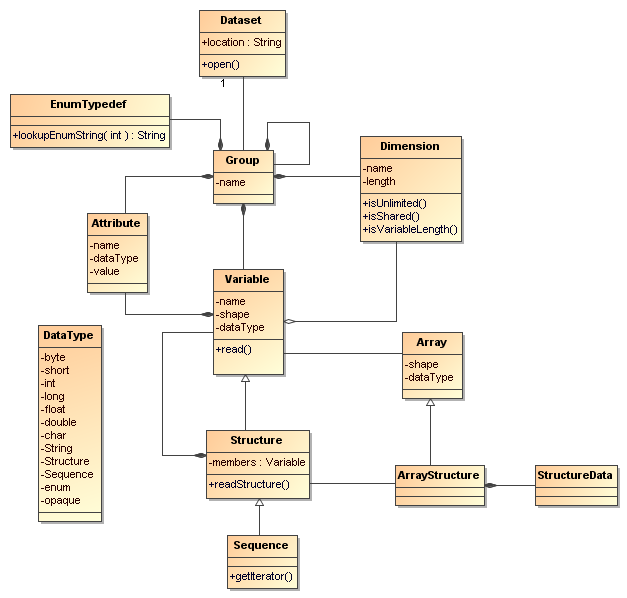
Annotated Schema
Aggregation specific elements are listed in red. The forecastModelRunCollection, forecastModelRunSingleCollection, joinExisting and joinNew aggregation types are called outer aggregations because they work on the outer (first) dimension.
schema Element
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema targetNamespace="http://www.unidata.ucar.edu/namespaces/netcdf/ncml-2.2"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns="http://www.unidata.ucar.edu/namespaces/netcdf/ncml-2.2"
elementFormDefault="qualified"
version="2.2.1">
netcdf Element
The element netcdf is the root tag of the NcML instance document, and is said to define a NetCDF dataset.
<!-- XML encoding of Netcdf container object -->
<xsd:element name="netcdf">
<xsd:complexType>
<xsd:sequence>
(1) <xsd:choice minOccurs="0">
<xsd:element name="readMetadata"/>
<xsd:element name="explicit"/>
</xsd:choice>
(2) <xsd:element name="iospParam" minOccurs="0" />
(3) <xsd:choice minOccurs="0" maxOccurs="unbounded">
<xsd:element ref="group"/>
<xsd:element ref="dimension"/>
<xsd:element ref="variable"/>
<xsd:element ref="attribute"/>
<xsd:element ref="remove"/>
</xsd:choice>
(4) <xsd:element ref="aggregation" minOccurs="0"/>
</xsd:sequence>
(5)<xsd:attribute name="location" type="xsd:anyURI"/>
(6)<xsd:attribute name="id" type="xsd:string"/>
(7)<xsd:attribute name="title" type="xsd:string"/>
(8)<xsd:attribute name="enhance" type="xsd:string"/>
(9)<xsd:attribute name="addRecords" type="xsd:boolean"/>
(10)<xsd:attribute name="iosp" type="xsd:string"/>
<xsd:attribute name="iospParam" type="xsd:string"/>
<xsd:attribute name="bufferSize" type="xsd:int"/>
<!-- for netcdf elements nested inside of aggregation elements -->
(11)<xsd:attribute name="ncoords" type="xsd:string"/>
(12)<xsd:attribute name="coordValue" type="xsd:string"/>
(13)<xsd:attribute name="section" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
- A readMetadata (default) or an explicit element comes first. The readMetadata element indicates that all the metadata from the referenced dataset will be read in. The explicit element indicates that only the metadata explictly declared in the NcML file will be used.
- An optional iospParam element. The NcML inside this element is passed directly to the IOSP. If an iospParam attribute is used, the attribute is used instead.
- The netcdf element may contain any number (including 0) of elements group, variable, dimension, or attribute that can appear in any order. If you use readMetadata, you can remove specific elements with the remove element.
- An aggregation element is used to logically join multiple netcdf datasets into a single dataset.
- The optional location attribute provides a reference to another netCDF dataset, called the referenced dataset. The location can be an absolute URL (eg http://server/myfile, or file:/usr/local/data/mine.nc) or a URL relative to the NcML location (eg subdir/mydata.nc). The referenced dataset contains the variable data that is not explicitly specified in the NcML document itself. If the location is missing and the data is not defined in values elements, then an empty file is written similar to the way CDL files are written by ncgen.
- The optional id attribute is meant to provide a way to uniquely identify (relative to the application context) the NetCDF dataset. It is important to understand that the id attribute refers to the NetCDF dataset defined by the XML instance document, NOT the referenced dataset if there is one.
- The optional title attribute provides a way to add a human readable title to the netCDF dataset.
- The optional enhance attribute indicates whether the referenced dataset is opened in enhanced mode, and can be set to All, AllDefer, ScaleMissing, ScaleMissingDefer, CoordSystems, or None (case insensitive). For backwards compatibility, a value of true means All. Default is None. See NetcdfDataset.EnhanceMode.
- The optional addRecords attribute is used only when the referenced datasets is a netCDF-3 file. If true (default false) then a Structure named record is added, containing the record (unlimited) variables. This allows one to read efficiently along the unlimited dimension.
- These 3 parameters control how the referenced dataset is opened by the IOServiceProvider. If iosp is specified, its value must be a fully qualified class name of an IOServiceProvider class that knows how to open the file specified by location. The optional iospParam is passed to the IOSP through the IOServiceProvider.setSpecial() method. The optional bufferSize tells the IOSP how many bytes to use for buffering the file data.
- The optional ncoords attribute is used for joinExisting aggregation datasets to indicate the number of coordinates that come from the dataset. This is used to avoid having to open each dataset when starting.
- The coordValue attribute is used for joinExisting or joinNew aggregations to assign a coordinate value(s) to the dataset. A joinNew aggregation always has exactly one coordinate value. A joinExisting may have multiple values, in which case, blanks and/or commas are used to delineate them, so you cannot use those characters in your coordinate values.
- The section attribute is used only for tiled aggregations, and describes which section of the entire dataset this dataset represents. The section value follows the ucar.ma2.Section section spec (see javadocs), eg "(1:20,:,3)", parenthesis optional
An example:
<?xml version="1.0" encoding="UTF-8"?>
<netcdf xmlns="http://www.unidata.ucar.edu/namespaces/netcdf/ncml-2.2"
location="C:/dev/github/thredds/cdm/src/test/data/testWrite.nc">
<dimension name="lat" length="64" />
<dimension name="lon" length="128" />
<dimension name="names_len" length="80" />
<dimension name="names" length="3" />
<variable name="names" type="char" shape="names names_len" />
<variable name="temperature" shape="lat lon" type="double">
<attribute name="units" value="K" />
<attribute name="scale" type="int" value="1 2 3" />
</variable>
</netcdf>
group Element
A group element represents a netCDF group, a container for variable, dimension, attribute, or other group elements.
<xsd:element name="group">
<xsd:complexType>
(1)<xsd:choice minOccurs="0" maxOccurs="unbounded">
<xsd:element ref="enumTypedef"/>
<xsd:element ref="dimension"/>
<xsd:element ref="variable"/>
<xsd:element ref="attribute"/>
<xsd:element ref="group"/>
<xsd:element ref="remove"/>
</xsd:choice>
(2)<xsd:attribute name="name" type="xsd:string" use="required"/>
(3)<xsd:attribute name="orgName" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
- The group element may contain any number (including 0) of elements group, variable, dimension, or attribute that can appear in any order. You can also mix in remove elements to remove elements coming from the referenced dataset.
- The mandatory name attribute must be unique among groups within its containing group or netcdf element.
- The optional attribute orgName is used when renaming a group.
dimension Element
The dimension element represents a netCDF dimension, i.e. a named index of specified length.
<!-- XML encoding of Dimension object -->
<xsd:element name="dimension">
<xsd:complexType>
(1) <xsd:attribute name="name" type="xsd:token" use="required"/>
(2) <xsd:attribute name="length" type="xsd:string"/>
(3) <xsd:attribute name="isUnlimited" type="xsd:boolean" default="false"/>
(4) <xsd:attribute name="isVariableLength" type="xsd:boolean" default="false"/>
(5) <xsd:attribute name="isShared" type="xsd:boolean" default="true"/>
(6) <xsd:attribute name="orgName" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
- The mandatory name attribute must be unique among dimensions within its containing group or netcdf element.
- The mandatory attribute length expresses the cardinality (number of points) associated with the dimension. Its value can be any non negative integer including 0 (since the unlimited dimension in a netCDF file may have length 0, corresponding to 0 records). A variable length dimension should be given length=”*”.
- The attribute isUnlimited is true only if the dimension can grow (a.k.a the record dimension in NetCDF-3 files), and false when the length is fixed at file creation.
- The attribute isVariableLength is used for variable length data types, where the length is not part of the metadata..
- The attribute isShared is true for shared dimensions, and false when the dimension is private to the variable.
- The optional attribute orgName is used when renaming a dimension.
variable Element
A variable element represents a netCDF variable, i.e. a scalar or multidimensional array of specified type indexed by 0 or more dimensions.
<xsd:element name="variable">
<xsd:complexType>
<xsd:sequence>
(1) <xsd:element ref="attribute" minOccurs="0" maxOccurs="unbounded"/>
(2) <xsd:element ref="values" minOccurs="0"/>
(3) <xsd:element ref="variable" minOccurs="0" maxOccurs="unbounded"/>
(4) <xsd:element ref="logicalSection" minOccurs="0"/>
(5) <xsd:element ref="logicalSlice" minOccurs="0"/>
(6) <xsd:element ref="remove" minOccurs="0" maxOccurs="unbounded" />
</xsd:sequence>
(7) <xsd:attribute name="name" type="xsd:token" use="required" />
(8) <xsd:attribute name="type" type="DataType" use="required" />
(9) <xsd:attribute name="typedef" type="xsd:string"/>
(10) <xsd:attribute name="shape" type="xsd:token" />
(11) <xsd:attribute name="orgName" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
- A variable element may contain 0 or more attribute elements,
- The optional values element is used to specify the data values of the variable. The values must be listed compatibly with the size and shape of the variable (slowest varying dimension first). If not specified, the data values are taken from the variable of the same name in the referenced dataset. Values are the “raw values”, and will have scale.offset/missing applied to them if those attributes are present.
- A variable of data type structure may have nested variable elements within it.
- Create a logical section of this variable.
- Create a logical slice of this variable, where one of the dimensions is set to a constant.
- You can remove attributes from the underlying variable.
- The mandatory name attribute must be unique among variables within its containing group, variable, or netcdf element.
- The type attribute is one of the enumerated DataTypes.
- The typedef is the name of an enumerated Typedef. Can be used only for type=enum1, enum2 or enum4.
- The shape attribute lists the names of the dimensions the variable depends on. For a scalar variable, the list will be empty. The dimension names must be ordered with the slowest varying dimension first (same as in the CDL description). Anonymous dimensions are specified with just the integer length. For backwards compatibility, scalar variables may omit this attribute, although this is deprecated.
- The optional attribute orgName is used when renaming a variable. .
values Element
A values element specifies the data values of a variable, either by listing them for example:
<xsd:element name="values">
<xsd:complexType mixed="true">
(1) <xsd:attribute name="start" type="xsd:float"/>
<xsd:attribute name="increment" type="xsd:float"/>
<xsd:attribute name="npts" type="xsd:int"/>
(2) <xsd:attribute name="separator" type="xsd:string" />
(3) <xsd:attribute name="fromAttribute" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
- The values can be specified with a start and increment attributes, if they are numeric and evenly spaced. You can enter these as integers or floating point numbers, and they will be converted to the data type of the variable. The number of points will be taken from the shape of the variable. (For backwards compatibility, an npts attribute is allowed, although this is deprecated and ignored).
- By default, the list of values are separated by whitespace but a different token can be specified using the separator attribute. This is useful if you are entering String values, e.g.
My dog*has*fleas defines three Strings. - The values can be specified from a global or variable attribute. To specify a global attribute, use @gattname. For a variable attibute use varName@attName. The data type and the shape of the variable must agree with the attribute.
attribute Element
The attribute elements represents a netCDF attribute, i.e. a name-value pair of specified type. Its value may be specified in the value attribute or in the element content.
<xsd:element name="attribute">
<xsd:complexType mixed="true">
(1) <xsd:attribute name="name" type="xsd:token" use="required"/>
(2) <xsd:attribute name="type" type="DataType" default="String"/>
(3) <xsd:attribute name="value" type="xsd:string" />
(4) <xsd:attribute name="separator" type="xsd:string" />
(5) <xsd:attribute name="orgName" type="xsd:string"/>
(6) <xsd:attribute name="isUnsigned" type="xsd:boolean"/>
</xsd:complexType>
</xsd:element>
- The mandatory name attribute must be unique among attributes within its containing group, variable, or netcdf element.
- The type attribute may be String, byte, short, int, long, float, double. If not specified, it defaults to a String.
- The value attribute contains the actual data of the attribute element. In the most common case of single-valued attributes, a single number or string will be listed (as in value=”3.0”), while in the less frequent case of multi-valued attributes, all the numbers will be listed and separated by a blank or optionally some other character (as in value=”3.0 4.0 5.0”). Values can also be specified in the element content:
<?xml version="1.0" encoding="UTF-8"?>
<netcdf xmlns="http://www.unidata.ucar.edu/namespaces/netcdf/ncml-2.2">
<attribute name="actual_range" type="int" value="1 2" />
<attribute name="factual_range" type="int">1 2</attribute>
</netcdf>
- By default, if the attribute has type String, the entire value is taken as the attribute value, and if it has type other than String, then the list of values are separated by whitespace. A different token seperator can be specified using the separator attribute.
- The optional attribute orgName is used when renaming an existing attribute.
- The attribute’s values may be unsigned (if byte, short, int or long). By default, they are signed.
DataType Type
The DataType Type is an enumerated list of the data types allowed for NcML Variable objects.
<xsd:simpleType name="DataType">
<xsd:restriction base="xsd:token">
<xsd:enumeration value="byte"/>
<xsd:enumeration value="char"/>
<xsd:enumeration value="short"/>
<xsd:enumeration value="int"/>
<xsd:enumeration value="long"/>
<xsd:enumeration value="float"/>
<xsd:enumeration value="double"/>
<xsd:enumeration value="String"/>
<xsd:enumeration value="string"/>
<xsd:enumeration value="Structure"/>
<xsd:enumeration value="Sequence"/>
<xsd:enumeration value="opaque"/>
<xsd:enumeration value="enum1"/>
<xsd:enumeration value="enum2"/>
<xsd:enumeration value="enum4"/>
</xsd:restriction>
</xsd:simpleType>
- Unsigned integer types (byte, short, int) are indicated with an _Unsigned = “true” attribute on the Variable.
- A Variable with type enum1. enum2 or enum4 will refer to a enumTypedef object. Call Variable.getEnumTypedef().
enumTypedef Element
The enumTypedef element defines an enumeration.
<xsd:element name="enumTypedef">
<xsd:complexType mixed="true">
<xsd:sequence>
<xsd:element name="map" minOccurs="1" maxOccurs="unbounded">
<xsd:complexType mixed="true">
<xsd:attribute name="value" type="xsd:string" use="required"/>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="name" type="xsd:token" use="required"/>
<xsd:attribute name="type" type="DataType" default="enum1"/>
</xsd:complexType>
</xsd:element>
Example:
<?xml version="1.0" encoding="UTF-8"?>
<netcdf xmlns="http://www.unidata.ucar.edu/namespaces/netcdf/ncml-2.2" location="Q:/cdmUnitTest/formats/netcdf4/tst/test_enum_type.nc">
<enumTypedef name="cloud_class_t" type="enum1">
<enum key="0">Clear</enum>
<enum key="1">Cumulonimbus</enum>
<enum key="2">Stratus</enum>
<enum key="3">Stratocumulus</enum>
<enum key="4">Cumulus</enum>
<enum key="5">Altostratus</enum>
<enum key="6">Nimbostratus</enum>
<enum key="7">Altocumulus</enum>
<enum key="8">Cirrostratus</enum>
<enum key="9">Cirrocumulus</enum>
<enum key="10">Cirrus</enum>
<enum key="255">Missing</enum>
</enumTypedef>
<dimension name="station" length="5" />
<variable name="primary_cloud" shape="station" type="enum1">
<attribute name="_FillValue" value="Missing" />
</variable>
</netcdf>
remove Element
The remove element is used to remove attribute, dimension, variable or group objects that are in the referenced dataset. Place the remove element in the container of the object to be removed.
<xsd:element name="remove">
<xsd:complexType>
(1) <xsd:attribute name="name" type="xsd:string" use="required"/>
(2) <xsd:attribute name="type" type="ObjectType" use="required"/>
</xsd:complexType>
</xsd:element>
<xsd:simpleType name="ObjectType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="attribute"/>
<xsd:enumeration value="dimension"/>
<xsd:enumeration value="variable"/>
<xsd:enumeration value="group"/>
</xsd:restriction>
</xsd:simpleType>
- The name of the object to remove
- The type of the object to remove: attribute, dimension, variable or group.
logical view Elements
(since version 4.4)
These allow a variable to be a logical view of the original variable. Only one of the logical views can be used per variable.
<!-- logical view: use only a section of original -->
<xsd:element name="logicalSection">
<xsd:complexType>
<xsd:attribute name="section" type="xsd:token" use="required"/> <!-- creates anonymous dimensions -->
</xsd:complexType>
</xsd:element>
<xsd:element name="logicalSlice">
<xsd:complexType>
<xsd:attribute name="dimName" type="xsd:token" use="required"/>
<xsd:attribute name="index" type="xsd:int" use="required"/>
</xsd:complexType>
</xsd:element>
<xsd:element name="logicalReduce">
<xsd:complexType>
<xsd:attribute name="dimNames" type="xsd:string" use="required"/>
</xsd:complexType>
</xsd:element>
logicalReduce example:
The original variable has dimensions of length=1 named “latitude” and “longitude” :
<dimension name="time" length="143" />
<dimension name="pressure" length="63" />
<dimension name="latitude" length="1" />
<dimension name="longitude" length="1" />
<variable name="temperature" shape="time pressure latitude longitude" type="float">
<attribute name="long_name" value="Sea Temperature" />
<attribute name="units" value="Celsius" />
</variable>
Here is the NcML to remove them:
<variable name="temperature">
<logicalReduce dimNames="latitude longitude" />
</variable>
Everything following pertains to aggregation, and can be ignored if you are not using aggregation.
aggregation Element
The aggregation element allows multiple datasets to be combined into a single logical dataset. There can only be one aggregation element in a netcdf element.
<xsd:element name="aggregation">
<xsd:complexType>
<xsd:sequence>
(1) <xsd:choice minOccurs="0" maxOccurs="unbounded">
<xsd:element ref="group"/>
<xsd:element ref="dimension"/>
<xsd:element ref="variable"/>
<xsd:element ref="attribute"/>
<xsd:element ref="remove"/>
</xsd:choice>
(2) <xsd:element name="variableAgg" minOccurs="0" maxOccurs="unbounded">
<xsd:complexType>
<xsd:attribute name="name" type="xsd:string" use="required"/>
</xsd:complexType>
</xsd:element>
(3) <xsd:element ref="promoteGlobalAttribute" minOccurs="0" maxOccurs="unbounded"/>
(4) <xsd:element ref="cacheVariable" minOccurs="0" maxOccurs="unbounded"/>
(5) <xsd:element ref="netcdf" minOccurs="0" maxOccurs="unbounded"/>
(6) <xsd:element name="scan" minOccurs="0" maxOccurs="unbounded">
<xsd:complexType>
(7) <xsd:attribute name="location" type="xsd:string" use="required"/>
(8) <xsd:attribute name="regExp" type="xsd:string" />
(9) <xsd:attribute name="suffix" type="xsd:string" />
(10) <xsd:attribute name="subdirs" type="xsd:boolean" default="true"/>
(11) <xsd:attribute name="olderThan" type="xsd:string" />
(12) <xsd:attribute name="dateFormatMark" type="xsd:string" />
(13) <xsd:attribute name="enhance" type="xsd:string"/>
(14) <xsd:attribute name="numericTimeSettings" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
(15) <xsd:element name="scanFmrc" minOccurs="0" maxOccurs="unbounded">
<xsd:complexType>
(7) <xsd:attribute name="location" type="xsd:string"
(8) <xsd:attribute name="regExp" type="xsd:string" />use="required"/>
(9) <xsd:attribute name="suffix" type="xsd:string" />
(10) <xsd:attribute name="subdirs" type="xsd:boolean" default="true"/>
(11) <xsd:attribute name="olderThan" type="xsd:string" />
(16) <xsd:attribute name="runDateMatcher" type="xsd:string" />
<xsd:attribute name="forecastDateMatcher" type="xsd:string" />
<xsd:attribute name="forecastOffsetMatcher" type="xsd:string" />
</xsd:complexType>
</xsd:element>
</xsd:sequence>
(17) <xsd:attribute name="type" type="AggregationType" use="required"/>
(18) <xsd:attribute name="dimName" type="xsd:token" />
(19) <xsd:attribute name="recheckEvery" type="xsd:string" />
(20) <xsd:attribute name="timeUnitsChange" type="xsd:boolean"/>
<!-- fmrc only -->
(21) <xsd:attribute name="fmrcDefinition" type="xsd:string" />
</xsd:complexType>
</xsd:element>
- These are the elements inside the <aggregation> which get applied to each dataset in the aggregation, before it is aggregated. Elements outside the <aggregation> get applied to the aggregated dataset.
- For joinNew aggregation types, each variable to be aggregated must be explicitly listed in a variableAgg element.
- Optionally specify global attributes to promote to a variable (outer aggregations only) with a promoteGlobalAttribute element.
- Specify which variables should be cached (outer aggregation only) with a cacheVariable element.
- Nested netcdf datasets can be explicitly listed.
- Nested netcdf datasets can be implicitly specified with a scan element.
- The scan directory location.
- If you specify a regExp, only files with whose full pathnames match the regular expression will be included.
- If you specify a suffix, only files with that ending will be included. A regExp attribute will override, that is, you cant specify both.
- You can optionally specify with subdir whether the scan should descend into subdirectories (default true).
- If olderThan attribute is present, only files whose last modified date are older than this amount of time will be included. This is a way to exclude files that are still being written. This must be a udunit time such as “5 min” or “1 hour”.
- A dateFormatMark is used on joinNew types to create date coordinate values out of the filename. See more below.
- You can optionally specify that the files should be opened in enhance mode (default is None). Generally you should do this if the ncml needs to operate on the dataset after the CoordSysBuilder has augmented it. Otherwise, you should not enhance.
- numericTimeSettings is used in conjunction with dateFormatMark to create a numeric, UDUNITS compatible aggregated time variable. See more below.
- A specialized scanFmrc element can be used for a forecastModelRunSingleCollection aggregation, where forecast model run data is stored in multiple files, with one forecast time per file.
- For scanFmrc, the run date and the forecast date is extracted from the file pathname using a runDateMatcher and either a forecastDateMatcher or a forecastOffsetMatcher attribute. See more below.
- You must specify an aggregation type.
- For all types except joinUnion, you must specify the dimension name to join.
- The recheckEvery allows you to rescan periodically to see if the set of files has changed.
- Only for joinExisting and forecastModelRunCollection types: if timeUnitsChange is set to true, the units of the joined coordinate variable may change, so examine them and do any appropriate conversion so that the aggregated coordinate values have consistent units.
- Experimental, do not use.
DateFormatMark
A dateFormatMark is used on joinNew types to create date coordinate values out of the filename. It consists of a section of text, a ‘#’ marking character, then a java.text.SimpleDateFormat string. The number of characters before the # is skipped in the filename, then the next part of the filename must match the SimpleDateFormat string. You can ignore trailing text. For example:
Filename: SUPER-NATIONAL_1km_SFC-T_20051206_2300.gini
DateFormatMark: SUPER-NATIONAL_1km_SFC-T_#yyyyMMdd_HHmm
Note that the dateFormatMark works on the name of the file, without the directories!! A dateFormatMark can be used on a joinExisting type only if there is a single time in each file of the aggregation, in which case the coordinate values of the time can be created from the filename, instead of having to open each file and read it.
numericTimeSettings
numericTimeSettings can be combined with a dateFormatMark to produce a numeric, UDUNITS compatible time variable. numericTimeSettings consists of a data type plus a UDUNITS compatible time unit. Care must be taken when choosing these parameters to prevent truncation.
Filename: SUPER-NATIONAL_1km_SFC-T_20051206_2300.gini
DateFormatMark: SUPER-NATIONAL_1km_SFC-T_#yyyyMMdd_HHmm
numericTimeSettings: int minutes since 2005-12-01T00:00:00Z"
ScanFmrc
The run date and the forecast date is extracted from the file pathname using a runDateMatcher and either a forecastDateMatcher or a forecastOffsetMatcher attribute. All of these require matching a specific string in the file’s pathname and then matching a date or hour offset immediately before or after the match. The match is specified by placing it between ‘#’ marking characters. The runDateMatcher and forecastDateMatcher has a java.text.SimpleDateFormat string before or after the match, while a forecastOffsetMatcher counts the number of ‘H’ characters, and extracts an hour offset from the run date. For example:
Filename: gfs_3_20060706_0300_006.grb
runDateMatcher: #gfs_3_#yyyyMMdd_HH
forecastOffsetMatcher: HHH#.grb#
will extract the run date 2006-07-06T03:00:00Z, and the forecast offset “6 hours”.
Recheck Scan (LOOK: deprecated ??)
When you are using scan elements on a set of files that may change, and you are using caching, set recheckEvery to a valid udunit time value, like “10 min”, “1 hour”, “30 days”, etc. Whenever the dataset is reacquired from the cache, the directories will be rescanned if recheckEvery amount of time has elapsed since the last time it was scanned. If you do not specify a recheckEvery attribute, the collection is assumed to be non-changing.
The recheckEvery attribute specifies how out-of-date you are willing to allow your changing datasets to be, not how often the data changes. If you want updates to be seen within 5 min, use 5 minutes here, regardless of the frequency of updating.
AggregationType Type
<!-- type of aggregation -->
<xsd:simpleType name="AggregationType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="forecastModelRunCollection"/>
<xsd:enumeration value="forecastModelRunSingleCollection"/>
<xsd:enumeration value="joinExisting"/>
<xsd:enumeration value="joinNew"/>
<xsd:enumeration value="tiled"/>
<xsd:enumeration value="union"/>
</xsd:restriction>
</xsd:simpleType>
The allowable aggregation types. The forecastModelRunCollection, forecastModelRunSingleCollection, joinExisting and joinNew aggregation types are called outer aggregations because they work on the outer (first) dimension.
promoteGlobalAttribute Element
<!-- promote global attribute to variable -->
<xsd:element name="promoteGlobalAttribute">
<xsd:complexType>
(1) <xsd:attribute name="name" type="xsd:token" use="required"/>
(2) <xsd:attribute name="orgName" type="xsd:string"/>
</xsd:complexType>
</xsd:element>
- The name of the variable to be created.
- If the global attribute name is different from the variable name, specify it here.
This can be used on joinNew, joinExisting, and forecastModelRunCollection, aka the outer dimension aggregations. A new variable will be added using the aggregation dimension and its type will be taken from the attribute type. If theres more than one slice in the file (eg in a joinExisting), the attribute value will be repeated for each coordinate in that file.
cacheVariable Element
<!-- cache a Variable for efficiency -->
<xsd:element name="cacheVariable">
<xsd:complexType>
<xsd:attribute name="name" type="xsd:token" use="required"/>
</xsd:complexType>
</xsd:element>
Not ready to be used in a general way yet.
Notes
- Any attributes of type xsd:token, have trailing and ending spaces ignored, and all other spaces or new lines are collapsed to one single space.
- If any attribute or content has the characters ">", "<", """, or "&", they must be encoded using standard XML escape sequences >, <, ", & respectively.
The java.text.SimpleDateFormat
NcML uses the java.text.SimpleDateFormat class for date and time formatting. Refer to the current javadoc for details.
Examples
The following examples show how date and time patterns are interpreted in the U.S. locale. The given date and time are 2001-07-04 12:08:56 local time in the U.S. Pacific Time time zone.
| Date and Time Pattern | Result |
|---|---|
| “yyyy.MM.dd G ‘at’ HH:mm:ss z” | 2001.07.04 AD at 12:08:56 PDT |
| “EEE, MMM d, ‘‘yy” | Wed, Jul 4, ‘01 |
| “h:mm a” | 12:08 PM |
| “hh ‘o’‘clock’ a, zzzz” | 12 o’clock PM, Pacific Daylight Time |
| “K:mm a, z” | 0:08 PM, PDT |
| “yyyyy.MMMMM.dd GGG hh:mm aaa” | 02001.July.04 AD 12:08 PM |
| “EEE, d MMM yyyy HH:mm:ss Z” | Wed, 4 Jul 2001 12:08:56 -0700 |
| “yyMMddHHmmssZ” | 010704120856-0700 |
Regular Expressions
Regular expressions are used in </b>scan</b> elements to match filenames to be included in the aggregation. Note that the regexp pattern is matched against the full pathname of the file (/dir/file.nc, not file.nc).
When placing regular expressions in NcML, you dont need to use \ for \, eg use
<scan location="test" regExp=".*/AG.*\.nc$" />
instead of
<scan location="test" regExp=".*/AG.*\\.nc$" />
This may be confusing if you are used to having to double escape in Java Strings:
Pattern.compile(“./AG.\.nc$”)
Examples
| Pattern | File Pathname | match? |
|---|---|---|
| ./AG..nc$ | C:/data/test/AG2006001_2006003_ssta.nc | true |
| ./AG..nc$ | C:/data/test/AG2006001_2006003_ssta.ncd | false |
| ./AG..nc$ | C:/data/test/PS2006001_2006003_ssta.ncs | false |