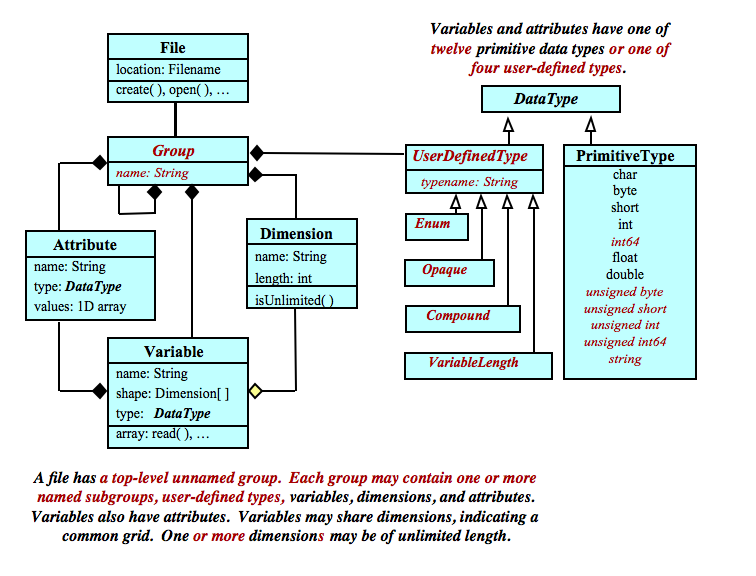
The Enhanced Data Model adds groups, a string type, several unsigned integer types, and four kinds of user-defined types (see User Defined Data Types). Groups, like directories in a file system, can be hierarchically organized to arbitrary depth. Each netCDF dataset contains a top-level, unnamed root group (“/”). Each group may contain one or more named variables, dimensions, attributes, groups, and user-defined types.
A variable is still a multidimensional array whose elements are all of the same type. Each variable may have attributes, and each variable’s shape is specified by its dimensions, which may be shared. However, in the enhanced data model, one or more dimensions may be of unlimited length, so data may be efficiently appended to variables along any of those dimensions. Variables and attributes have one of twelve primitive data types or one of four kinds of user-defined types.
Dimensions are scoped such that they can be seen in all descendant groups. That is, dimensions can be shared between variables in different groups, if they are defined in a parent group.
In netCDF-4 files, the user may also define a type. For example a compound type may hold information from an array of C structures, or a variable length type allows the user to read and write arrays of variable length values.
User-defined types are scoped such that they can be referenced in all other groups. That means, for example, that variables in different groups can have the same type.
Variables, groups, and types share a namespace. Within the same group, variables, groups, and types must have unique names. (That is, a type and variable may not have the same name within the same group, and similarly for sub-groups of that group.)
A diagram of the enhanced netCDF data model shows (in red) what it adds to the classic netCDF data model: