The featureCollection element is a way to tell the TDS to serve collections of CDM Feature Datasets.
Currently, this is used mostly for gridded data whose time and spatial coordinates are recognized by the CDM software stack.
This allows the TDS to automatically create logical datasets composed of collections of files, particularly gridded model data output, called Forecast Model Run Collections (FMRC).
A Forecast Model Run Collection is a collection of forecast model output.
A special kind of aggregation, called an FMRC Aggregation, creates a dataset that has two time coordinates, called the run time and the forecast time.
This dataset can then be sliced up in various ways to create 1D time views of the model output.
See this poster for a detailed example.
As of TDS 4.2, you should use the featureCollection element in your configuration catalog.
(The previous way of doing this was with a datasetFmrc element, which is now deprecated.)
The component files of the collection must all be recognized as a Grid Feature type by the CDM software.
Exercise: Creating Datasets Out Of The FMRC
Download catalogFmrc.xml, place it in your TDS ${tds.content.root.path}/thredds directory and add a catalogRef to it from your main catalog.
<?xml version="1.0" encoding="UTF-8"?>
<catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0"
xmlns:xlink="http://www.w3.org/1999/xlink" name="Unidata THREDDS Data Server" version="1.0.3">
<service name="fmrcServices" serviceType="Compound" base=""> <!-- 1 -->
<service name="ncdods" serviceType="OPENDAP" base="/thredds/dodsC/"/>
<service name="HTTPServer" serviceType="HTTPServer" base="/thredds/fileServer/"/>
<service name="wcs" serviceType="WCS" base="/thredds/wcs/"/>
<service name="wms" serviceType="WMS" base="/thredds/wms/"/>
<service name="ncss" serviceType="NetcdfSubset" base="/thredds/ncss/grid"/>
<service name="cdmremote" serviceType="CdmRemote" base="/thredds/cdmremote/"/>
<service name="ncml" serviceType="NCML" base="/thredds/ncml/"/>
<service name="uddc" serviceType="UDDC" base="/thredds/uddc/"/>
<service name="iso" serviceType="ISO" base="/thredds/iso/"/>
</service>
<dataset name="FMRC Example for tutorial">
<featureCollection name="BOM" featureType="FMRC" harvest="true" path="BOM"> <!-- 2 -->
<metadata inherited="true"> <!-- 3 -->
<serviceName>fmrcServices</serviceName>
<dataFormat>netCDF</dataFormat>
<documentation type="summary">Example BOM</documentation>
</metadata>
<collection spec="<path-to-data>/fmrc_tutorial/bom/**/ocean_fc_#yyyyMMdd#.*\.nc$"/> <!-- 4 -->
</featureCollection>
</dataset>
</catalog>
- All services are defined in a compound service type called
fmrcServices. - A THREDDS
featureCollectionis defined, of typeFMRC. All contained datasets will all have apathstarting withBOM/model. - All the
metadatacontained here will be inherited by the contained datasets. - The collection of files is defined, using a collection specification string.
Subdirectories of
<path-to-data>/fmrc_tutorial/bom/will be scanned for files with names that start withocean_fc_, and end with.nc. The run data is extracted from the filename.
The contained datasets include the resulting 2D time dimension dataset, as well as 1D time views described here, as seen in the resulting HTML page for that dataset:
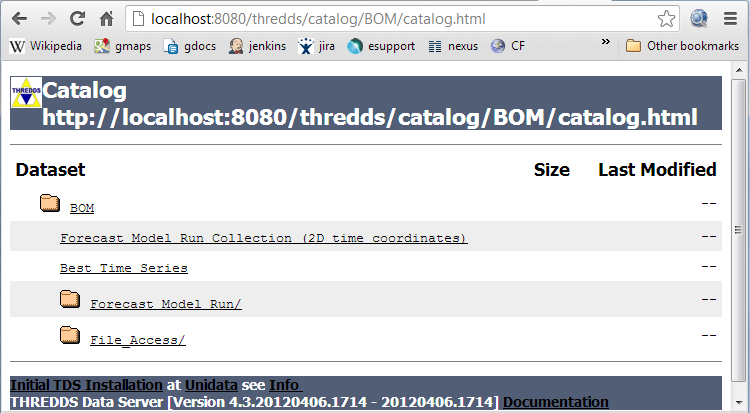
The TDS has created a number of datasets out of the FMRC, and made them available through the catalog interface.
Explore them through the browser, ToolsUI, the IDV, or Siphon.
Finally, what happens if we remove the service and serviceName elements, and restart the TDS?
Specifying The Run Time
FMRCs are collections of files with (possibly) different run times, and the software needs to know what that run time is.
If you look closely at the files in this example, you may notice that the run time does not appear explicitly inside the file anywhere.
Luckily the information is in the filename, which is a common practice.
-
The recommended way to specify the run time is to specify a date parsing template in the collection specification string, for example:
<collection spec="<path-to-data>/fmrc_tutorial/bom/**/ocean_fc_#yyyyMMdd#.*\.nc$" />Extracts the run date by applying the template
yyyyMMddto the portion of the filename after “ocean_fc_”.If the information is in a directory name, then you can use the
dateFormatMarkfield on the collection element. In our example, an example dataset paths looks like:/machine/tds/workshop/20090330/ocean_fc_20090330_048_eta.nc.If we wanted to extract the run time from the directory (pretending we couldn’t do that from the filename), this is how we would do that:
<collection spec="/machine/tds/workshop/bom/**/ocean_fc_.*\.nc$" dateFormatMark="#workshop/bom/#yyyyyMMdd" />Note that we:
- remove the date extractor from the collection specification string
- add a
dateFormatMarkattribute. In this case, the#characters delineate a substring match on the entire pathname (so there had better only be one place where the stringworkshop/bom/appears). Immediately following the match comes the date extractor string. See here for more details.
-
The second way to specify the run time is to add a global attribute inside each file of the collection, with name
_CoordinateModelRunDatewhose value is the run time as an ISO date string. For example::Conventions = "CF-1.4"; :Originating_center = "US National Weather Service - NCEP(WMC) (7)"; :Generating_Model = "Analysis from Global Data Assimilation System"; :_CoordinateModelRunDate = "2010-11-05T00:00:00Z";
Feature Collections That Change
The above example creates a static collection of files. A common case is that one has a collection of files that are changing, as files are added and deleted while being served through the TDS. Below is an example dataset, with additional elements and attributes to handle this case:
<catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0"
xmlns:xlink="http://www.w3.org/1999/xlink" name="Unidata THREDDS Data Server"
version="1.0.3">
<service name="ncdods" serviceType="OPENDAP" base="/thredds/dodsC/"/>
<featureCollection featureType="FMRC" name="NCEP-GFS_Global_2p5deg"
path="fmrc/NCEP/GFS/GFS_Global_2p5deg">
<metadata inherited="true">
<serviceName>ncdods</serviceName>
<dataFormat>netCDF-4</dataFormat>
<documentation type="summary">Specially good GFS_Global_2p5deg</documentation>
</metadata>
<collection spec="/machine/tds/workshop/gfs/GFS_Global_2p5deg.*\.nc4$"
name="GFS_Global_2p5deg"
recheckAfter="15 min" <!-- 1 -->
olderThan="5 min"/> <!-- 2 -->
<update startup="test" rescan="0 5 3 * * ? *" trigger="allow"/> <!-- 3 -->
<protoDataset choice="Penultimate" change="0 2 3 * * ? *" /> <!-- 4 -->
<fmrcConfig datasetTypes="TwoD Best Runs ConstantForecasts ConstantOffsets Files" /> <!-- 5 -->
</featureCollection>
</catalog>
recheckAfter: When a request comes in, if the collection hasn’t been checked for 15 minutes, check to see if it has changed. The request will wait until the rescan is finished and a new collection is built (if needed). This minimizes unneeded processing for lightly used collections.olderThan: Only files that haven’t changed for 5 minutes will be included. This excludes files that are in the middle of being written.update: The collection will be updated upon TDS startup, and periodically using the cron expression0 5 3 * * ? *, meaning every day at 3:05 am local time. This updating is done in the background, as opposed to when a request for it comes in.protoDataset: The prototypical dataset is chosen to be the “next-to-latest”. The prototypical dataset is changed every day at 3:02 am local time.fmrcConfig: The kinds of datasets that are created are listed explicitly. You can see how this corresponds directly to the HTML dataset page above. Remove the ones that you don’t want to make available. Default is “TwoD Best Files Runs”
The recheckAfter attribute and the update element are really alternate ways to specify rescanning strategies.
Use the update element on large collections when you want to ensure quick response.
Use the recheckAfter on lightly used collections in order to minimize server load.
Don’t use both of them on the same dataset on a real production server.
More details are in the FeatureCollection reference documentation.