Overview
All of the GRIB records in all of the files that you specify constitute a GRIB collection. The Common Data Model (CDM) creates one or more CDM datasets from this collection. There is always an overall collection dataset, and for large collections you may want to also present smaller subsets, for example yearly subsets of a multiyear model run. To do so, GRIB collections can be divided up into time partitions, based on the reference time of the GRIB records.
You may also want to partition your collection due to memory constraints or in order to speed up indexing.
To build an index, all of the metadata of each GRIB record is read into memory.
This is somewhere between 200-1000 bytes / record.
A good estimate is twice the sum of the sizes of all the GRIB index files (gbx9 files) in the collection.
This memory is only required when building the index, and after the indexes are built, the memory usage is proportional to the size of the CDM index files (ncx files).
For example, if you have 1 million records in your collection, you may need ~500 MB of main memory for the indexing. The time it takes to index also increases with the number of GRIB records (probably somewhat more than linearly). When your collection is changing, partitioned collections will only have to update the partitions that change. All of these are reasons you may want to use time partitioning.
Homogeneity Requirements
A feature collection dataset is a homogeneous collection of records. That means that the metadata describing the dataset is approximately the same for all of the records.
Each GRIB record is self-contained, in the sense that it does not reference other records, or an overall schema. The point of making a collection of GRIB records into a CDM dataset, is to allow the user to access the entire collection at once, using the netCDF API for multidimensionsal arrays. The user cannot, using the netCDF API, access the metadata for individual GRIB records. Instead, we assume that the metadata is uniform in the collection, and expose it with variable and global attributes.
Time Partitions
A time partition is the partitioning of the GRIB records into disjoint sets, based on the reference time of the GRIB records. (For model runs the reference time is usually the model run time).
The partitioning is controlled by the timePartition attribute on the <collection> element inside the <featureCollection>, e.g.:
<featureCollection name="NCEP GFS model" featureType="GRIB1" path="test/all">
<metadata inherited="true">
<serviceName>all</serviceName>
<dataFormat>GRIB-1</dataFormat>
</metadata>
<collection name="gfs" spec="/data/GFS/**/.*\.grb$" timePartition="directory"/>
</featureCollection>
For each partition, a CDM index file is created, and a CDM collection dataset can be acccessed by the user.
The possible values of timePartition are:
directory: each directory is a partition. Nested directories create nested partitions (e.g., year/month/day).file: each file is a partition.-
<time unit>: the files are divided into partitions based on the given time unit. The reference time must be encoded in the filenames. This is the only time you need to use adateFormatMark. none: all files are scanned in, and one collection level index is built.
Directory Partition
In order to use a directory partition, the directory structure must partition the data by reference time.
That is, all of the data for any given reference time must be completely contained in the directory.
Directories can be nested to any level.
To use, add the attribute timePartition="directory", or simply omit, as this is the default.
File Partition
In order to use a file partition, all of the records for a reference time must be contained in a single file.
The common case is that each file contains all of the records for a single reference time.
To use, put timePartition="file".
Time Partition
In order to use a time partition, the filenames must contain parsable time information than can be used to partition the data. The directory layout, if any, is not used. The common case is where all files are in a single directory, and each file has the reference date encoded in the name. The split-out of variables does not matter.
If a collection is configured as a time partition, all of the filenames are read into memory at once.
A date extractor must be specified, and is used to group the files into partitions.
For example, if timePartition = "1 year", all of the files for each calendar year are made into a collection.
The overall dataset is the collection of all of those yearly collections.
None Partition
If a collection is configured with timePartition="none", all of the records’ metadata (excluding the data itself) will be read into memory at once.
A single top-level collection is written.
This option is good option for small-medium collections (say < 1M records) which are not time-partitioned by directory.
Note that this option takes the longest when indexing, and other strategies are preferred for large collections, especially if the collection is dynamic and must be re-indexed often.

Collection Storage Strategies
Assuming you have control over how GRIB records are stored in the files, here are some best practices to consider.
-
Generally, managing many small files has more overhead than managing smaller numbers of large files. For today’s disks, file sizes of 100 Mb - 10 Gb seems right. Keep the number of files in a directory small, a few hundred is best, and more than a thousand starts to make things like directory listings hard.
-
Partition your files by reference time, which typically is the model run time. Depending on size and number, you might create directories by day, month, year, etc.
-
When you have complete control over how the collection is stored on disk, and you want to optimize for fastest THREDDS indexing and retrieval, file partitions are recommended. Placing all of the records for a single reference time in a single file is often optimal. If there are a small number of records for each runtime ( < a few tens of thousands?) you might want to put more than one reference time in each file. It’s essential all the records for each runtime be in a single file.
-
GRIB files are unordered collections of GRIB records, and the CDM simply scans the files in the collection, looking for GRIB headers. So you can concatenate GRIB files together just using the
catcommand. You can also createtarfiles; the internal files are ignored and thetarfile simply is seen as a collection of GRIB records. Other archives which don’t compress are also usable. However,zipandgzipare not currently usable in this way. -
If you reorganize your file collection, delete any previous THREDDS index files (
.gbx9and.ncx4) and regenerate them with the TDM. If you store indexes separate from the data, make sure you track down those directories and delete old index files.
Examples
timePartition="none" Example
<featureCollection featureType="GRIB1"
name="gfsConus80_none" path="gribCollection/gfsConus80_none"> <!-- 1 -->
<metadata inherited="true"> <!-- 2 -->
<documentation type="summary">This dataset blah blah blah</documentation>
<documentation xlink:href="http://www.rda.ucar.edu/rda/docs#ds099.9"
xlink:title="RDA Information"/>
</metadata>
<collection name="ds099.9" <!-- 3 -->
spec="Q:/cdmUnitTest/gribCollections/rdavm/ds099.9/PofP/**/.*grib1" <!-- 4 -->
timePartition="none"/> <!-- 5 -->
<update startup="never" trigger="allow"/> <!-- 6 -->
<tdm rewrite="test" rescan="0 0/15 * * * ? *" /> <!-- 7 -->
<gribConfig datasetTypes="TwoD Latest Best" /> <!-- 8 -->
</featureCollection>
- A
featureCollectionmust have a name, afeatureTypeand apath(do not set anIDattribute). The name is “human readable” and may change at will. ThefeatureTypeattribute must now equalGRIB1orGRIB2, not plainGRIB. - A
featureCollectionis anInvDatasetobject, so it can contain any elements anInvDatasetcan contain, such as metadata. Do not setdataTypeordataFormat, as these are set automatically. In this example, we don’t set theserviceName, so the default service is used. - The
collectionnameshould be short but descriptive, it must be unique across all collections on your TDS, and should not change. - The collection specification (
spec) defines the collection of files that are in this dataset. - The
partitionTypeisnone. - This update element tells the TDS to use the existing indices, and to read them only when an external trigger is sent. This is the default behavior, so it could be omitted.
- This
tdmelement tells the THREDDS Data Manager to test every 15 minutes if the collection has changed, and to rewrite the indices when it has changed. - GRIB specific configuration (
gribConfig), in this case, says to add both the full 2D time collection dataset, theBest, and a resolver link to the latest file. In this case, all files are read in by the TDS and a single collection index is made. Two datasets (TwoDandBest) are created for the entire collection.
The simplified catalog looks like this:
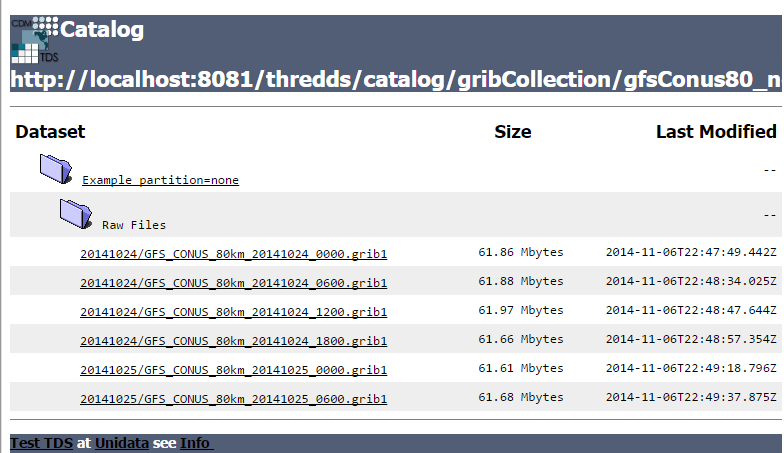
Under the hood:
<dataset name="NCEP GFS Puerto_Rico (191km)">
<metadata inherited="true">
<serviceName>VirtualServices</serviceName>
<dataType>GRID</dataType>
<dataFormat>GRIB-2</dataFormat>
</metadata>
<dataset name="Full Collection (Reference / Forecast Time) Dataset"
ID="fmrc/NCEP/GFS/Puerto_Rico/TwoD" urlPath="fmrc/NCEP/GFS/Puerto_Rico/TwoD">
<documentation type="summary">Two time dimensions: reference and forecast; full access to all GRIB records</documentation>
</dataset>
<dataset name="Best NCEP GFS Puerto_Rico (191km) Time Series"
ID="fmrc/NCEP/GFS/Puerto_Rico/Best" urlPath="fmrc/NCEP/GFS/Puerto_Rico/Best">
<documentation type="summary">Single time dimension: for each forecast time, use GRIB record with smallest offset from reference time</documentation>
</dataset>
<dataset name="Latest Collection for NCEP GFS Puerto_Rico (191km)" urlPath="latest.xml">
<serviceName>latest</serviceName>
</dataset>
</dataset>
timePartition="directory" Example
<featureCollection featureType="GRIB1" name="rdavm partition directory" path="gribCollection/pofp">
<collection name="ds083.2-directory"
spec="Q:/cdmUnitTest/gribCollections/rdavm/ds083.2/PofP/**/.*grib1"
timePartition="directory"/> <!-- 1 -->
</featureCollection>
- The collection is divided into partitions by directory. In order to use this, you cannot have two GRIB records with the same reference time in different directories.
timePartition="file" Example
<featureCollection featureType="GRIB1" name="rdavm partition directory" path="gribCollection/pofp">
<collection name="ds083.2-directory"
spec="Q:/cdmUnitTest/gribCollections/rdavm/ds083.2/PofP/**/.*grib1"
timePartition="file"/> <!-- 1 -->
</featureCollection>
- The collection is divided into partitions by files. In order to use this, you cannot have two GRIB records with the same reference time in different files.
A time partition generates one collection dataset, one dataset for each partition, and one dataset for each individual file in the collection:
<dataset name="NAM-Polar90" ID="grib/NCEP/NAM/Polar90">
<catalogRef xlink:href="/thredds/catalog/grib/NCEP/NAM/Polar90/collection/catalog.xml"
xlink:title="collection"/>
<catalogRef xlink:href="/thredds/catalog/grib/NCEP/NAM/Polar90/NAM-Polar90_20110301/catalog.xml"
xlink:title="NAM-Polar90_20110301">
<catalogRef xlink:href="/thredds/catalog/grib/NCEP/NAM/Polar90/NAM-Polar90_20110301/files/catalog.xml"
xlink:title="files" />
</catalogRef>
<catalogRef xlink:href="/thredds/catalog/grib/NCEP/NAM/Polar90/NAM-Polar90_20110302/catalog.xml"
xlink:title="NAM-Polar90_20110302">
<catalogRef xlink:href="/thredds/catalog/grib/NCEP/NAM/Polar90/NAM-Polar90_20110302/files/catalog.xml"
xlink:title="files" name="" />
</catalogRef>
...
</dataset>
De-referencing the catalogRefs and simplifying:
<dataset name="NAM-Polar90" ID="grib/NCEP/NAM/Polar90">
<dataset name="NAM-Polar90-collection"
urlPath="grib/NCEP/NAM/Polar90/collection"> <!-- 1 -->
<dataset name="NAM-Polar90_20110301"
urlPath="grib/NCEP/NAM/Polar90/NAM-Polar90_20110301/collection"> <!-- 2 -->
<dataset name="NAM_Polar_90km_20110301_0000.grib2"
urlPath="grib/NCEP/NAM/Polar90/files/NAM_Polar_90km_20110301_0000.grib2"/> <!-- 3 -->
<dataset name="NAM_Polar_90km_20110301_0600.grib2"
urlPath="grib/NCEP/NAM/Polar90/files/NAM_Polar_90km_20110301_0600.grib2"/>
...
</dataset>
<dataset name="NAM-Polar90_20110302-collection"
urlPath="grib/NCEP/NAM/Polar90/NAM-Polar90_20110302/collection"> <!-- 4 -->
<dataset name="NAM_Polar_90km_20110302_0000.grib2"
urlPath="grib/NCEP/NAM/Polar90/files/NAM_Polar_90km_20110302_0000.grib2"/>
<dataset name="NAM_Polar_90km_20110302_0600.grib2"
urlPath="grib/NCEP/NAM/Polar90/files/NAM_Polar_90km_20110302_0600.grib2"/>
...
</dataset>
...
</dataset>
- The overall collection dataset
- The first partition collection, with a
partitionName = name_startingTime - The files in the first partition
- The second partition collection, etc.
So the datasets that are generated from a Time Partition with name, path, and partitionName:
| dataset | catalogRef | name | path |
|---|---|---|---|
| collection | path/collection/catalog.xml | name | path/name/collection |
| partitions | path/partitionName/catalog.xml | partitionName | path/partitionName/collection |
| individual files | path/partitionName/files/catalog.xml | filename | path/files/filename |
Multiple Groups Example
When a Grib Collection contains multiple horizontal domains (i.e. distinct Grid Definition Sections (GDS)), each domain gets placed into a separate group.
As a rule, one can’t tell if there are separate domains without reading the files.
If you open this collection through the CDM (e.g., using ToolsUI) you would see a dataset that contains groups.
The TDS, however, separates groups into different datasets, so that each dataset has only a single (unnamed, aka root) group.
<featureCollection name="RFC" featureType="GRIB" path="grib/NPVU/RFC">
<metadata inherited="true">
<dataFormat>GRIB-1</dataFormat>
<serviceName>all</serviceName>
</metadata>
<collection spec="/tds2012data/grib/rfc/ZETA.*grib1$" dateFormatMark="yyyyMMdd#.grib1#"/>
<gribConfig> <!-- 1 -->
<gdsHash from="-752078894" to="1193085709"/>
<gdsHash hash='-1960629519' groupName='KTUA:Arkansas-Red River RFC'/>
<gdsHash hash='-1819879011' groupName='KFWR:West Gulf RFC'/>
<gdsHash hash='-1571856555' groupName='KORN:Lower Mississippi RFC'/>
<gdsHash hash='-1491065322' groupName='KKRF:Missouri Basin RFC'/>
<gdsHash hash='-1017807718' groupName='TSJU:San Juan PR WFO'/>
<gdsHash hash='-1003775954' groupName='NCEP-QPE National Mosaic'/>
<gdsHash hash='-529497359' groupName='KRHA:Middle Atlantic RFC'/>
<gdsHash hash='289752153' groupName='KRSA:California-Nevada RFC-6hr'/>
<gdsHash hash='424971237' groupName='KRSA:California-Nevada RFC-1hr'/>
<gdsHash hash='511861653' groupName='KTIR:Ohio Basin RFC'/>
<gdsHash hash='880498701' groupName='KPTR:Northwest RFC'/>
<gdsHash hash='1123818409' groupName='KTAR:Northeast RFC'/>
<gdsHash hash='1174418106' groupName='KNES-National Satellite Analysis'/>
<gdsHash hash='1193085709' groupName='KMSR:North Central RFC'/>
<gdsHash hash='1464276934' groupName='KSTR:Colorado Basin RFC'/>
<gdsHash hash='1815048381' groupName='KALR:Southeast RFC'/>
</gribConfig>
</featureCollection>
- This dataset has many different groups, and we are using a
<gribConfig>element to name them.
Resulting Datasets:
For each group, this generates one collection dataset, and one dataset for each individual file in the group:
<catalog>
<dataset name="KALR:Southeast RFC" urlPath="grib/NPVU/RFC/KALR-Southeast-RFC/collection">
<catalogRef xlink:href="/thredds/catalog/grib/NPVU/RFC/KALR-Southeast-RFC/files/catalog.xml"
xlink:title="files" name="" />
</dataset>
<dataset name="KFWR:West Gulf RFC" urlPath="grib/NPVU/RFC/KFWR-West-Gulf-RFC/collection">
<catalogRef xlink:href="/thredds/catalog/grib/NPVU/RFC/KFWR-West-Gulf-RFC/files/catalog.xml"
xlink:title="files" name="" />
</dataset>
...
</catalog>
Notice the groups are sorted by name and that there is no overall collection for the dataset. Simplifying:
<catalog>
<dataset name="KALR:Southeast RFC" urlPath="grib/NPVU/RFC/KALR-Southeast-RFC/collection"> <!-- 1 -->
<dataset name="ZETA_KALR_NWS_152_20120111.grib1"
urlPath="grib/NPVU/RFC/files/ZETA_KALR_NWS_152_20120111.grib1"/> <!-- 2 -->
<dataset name="ZETA_KALR_NWS_160_20120111.grib1"
urlPath="grib/NPVU/RFC/files/ZETA_KALR_NWS_160_20120111.grib1"/>
...
</dataset>
<dataset name="KFWR:West Gulf RFC" urlPath="grib/NPVU/RFC/KFWR-West-Gulf-RFC/collection"> <!-- 3 -->
<dataset name="ZETA_KFWR_NWS_152_20120111.grib1"
urlPath="grib/NPVU/RFC/files/ZETA_KFWR_NWS_152_20120111.grib1"/>
<dataset name="ZETA_KFWR_NWS_161_20120110.grib1"
urlPath="grib/NPVU/RFC/files/ZETA_KFWR_NWS_161_20120110.grib1"/>
...
</dataset>
...
</catalog>
- The first group collection dataset.
- The files in the first group.
- The second group collection dataset, etc.
So the datasets that are generated from a GRIB Collection with groupName and path:
| dataset | catalogRef | name | path |
|---|---|---|---|
| group collection | groupName | path/groupName/collection | |
| individual files | path/groupName/files/catalog.xml | filename | path/files/filename |
Time Partition with Multiple Groups Example
Here is a time-partitioned dataset with multiple groups:
<featureCollection name="NCDC-CFSR" featureType="GRIB" path="grib/NCDC/CFSR">
<metadata inherited="true">
<dataFormat>GRIB-2</dataFormat>
</metadata>
<collection spec="G:/nomads/cfsr/timeseries/**/.*grb2$"
timePartition="directory" <!-- 1 -->
dateFormatMark="#timeseries/#yyyyMM"/> <!-- 2 -->
<update startup="true" trigger="allow"/>
<gribConfig>
<gdsHash from="1450218978" to="1450192070"/> <!-- 3 -->
<gdsName hash='1450192070' groupName='FLX GaussianT382'/> <!-- 4 -->
<gdsName hash='2079260842' groupName='FLX GaussianT62'/>
...
<intvFilter excludeZero="true"/> <!-- 5 -->
</gribConfig>
</featureCollection>
- Partition the files by which directory they are in (the files must be time partitioned by the directories)
- One still needs a date extractor from the filename, even when using a directory partition.
- Minor errors in GRIB coding can create spurious differences in the GDS. Here we correct one such problem.
- Group renaming.
- Exclude GRIB records that have a time coordinate interval of
(0,0).
Resulting Datasets:
A time partition with multiple groups generates an overall collection dataset for each group, a collection dataset for each group in each partition, and a dataset for each individual file:
<dataset name="NCDC-CFSR" ID="grib/NCDC/CFSR">
<catalogRef xlink:href="/thredds/catalog/grib/NCDC/CFSR/collection/catalog.xml" xlink:title="collection" name="" /> <!-- 1 -->
<catalogRef xlink:href="/thredds/catalog/grib/NCDC/CFSR/200808/catalog.xml" xlink:title="200808" name="" /> <!-- 4 -->
<catalogRef xlink:href="/thredds/catalog/grib/NCDC/CFSR/200809/catalog.xml" xlink:title="200809" name="" /> <!-- 8 -->
...
</dataset>
De-referencing the catalogRefs and simplifying:
<dataset name="NCDC-CFSR" ID="grib/NCDC/CFSR">
<dataset name="NCDC-CFSR"> <!-- 1 -->
<dataset name="FLX GaussianT382" urlPath="grib/NCDC/CFSR/NCDC-CFSR/FLX-GaussianT382"/> <!-- 2 -->
<dataset name="FLX GaussianT62" urlPath="grib/NCDC/CFSR/NCDC-CFSR/FLX-GaussianT62"> <!-- 3 -->
...
</dataset>
<dataset name="200808"> <!-- 4 -->
<dataset name="FLX GaussianT382" urlPath="grib/NCDC/CFSR/200808/FLX-GaussianT382"> <!-- 5 -->
<catalogRef xlink:href="/thredds/catalog/grib/NCDC/CFSR/200808/FLX-GaussianT382/files/catalog.xml"
xlink:title="files" name="" /> <!-- 6 -->
</dataset>
<dataset name="FLX GaussianT62" urlPath="grib/NCDC/CFSR/200808/FLX-GaussianT62"> <!-- 7 -->
<catalogRef xlink:href="/thredds/catalog/grib/NCDC/CFSR/200808/FLX-GaussianT62/files/catalog.xml"
xlink:title="files" name="" />
</dataset>
...
</dataset>
<dataset name="200809"> <!-- 8 -->
...
</dataset>
- Container for the overall collection datasets.
- The overall collection for the first group.
- The overall collection for the second group, etc.
- Container for the first partition.
- The collection dataset for the first group of the first partition.
- The individual files for the first group of the first partition, etc.
- The collection dataset for the second group of the first partition, etc.
- Container for the second partition, etc.
So the datasets that are generated from a Time Partition with name, path, groupName, and partitionName:
| dataset | catalogRef | name | path |
|---|---|---|---|
| overall collection for group | path/groupName/collection/catalog.xml | groupName | path/name/groupName |
| collection for partition and group | path/partitionName/catalog.xml | groupName | path/partitionName/groupName |
| individual files | path/partitionName/groupName/files/catalog.xml | partitionName/filename | path/files/filename |